Our work sheds light on the current state of Rowhammer attacks and defenses by building an automated DRAM traffic analysis platform called McSee. Equipped with this platform, we analyze advanced Rowhammer(-like) attacks on DDR4 and the deployed mitigations in DDR5 systems. We find areas for improvement in existing attacks and show, for the first time, that CPU vendors do not send the necessary RFM commands to DRAM under a Rowhammer workload. We also find that Intel has deployed a pTRR mitigation in its Raptor Lake client CPUs.
The McSee Platform
Our platform is based on a high-speed oscilloscope with a 16-channel digitizer and a custom-designed UDIMM interposer. We optimize the scope acquisition pipeline by systematically benchmarking it and optimizing the bottlenecks. By leveraging hardware and software optimizations, we can increase the performance of a 2ms acquisition from initially 898s down to 55s — a speedup of 16x.
A core part of McSee is our DDR4/5 protocol decoder, which enables us to convert captured traces into DRAM commands automatically. This decoder follows the command encoding outlined in the JEDEC DDR4/5 standards. As our oscilloscope requires oversampling of the DRAM bus signals, we developed a three-step decoding process to decode DRAM commands reliably. We validate our platform and decoder using custom tests that we derived from the DRAM standard.
 |  |
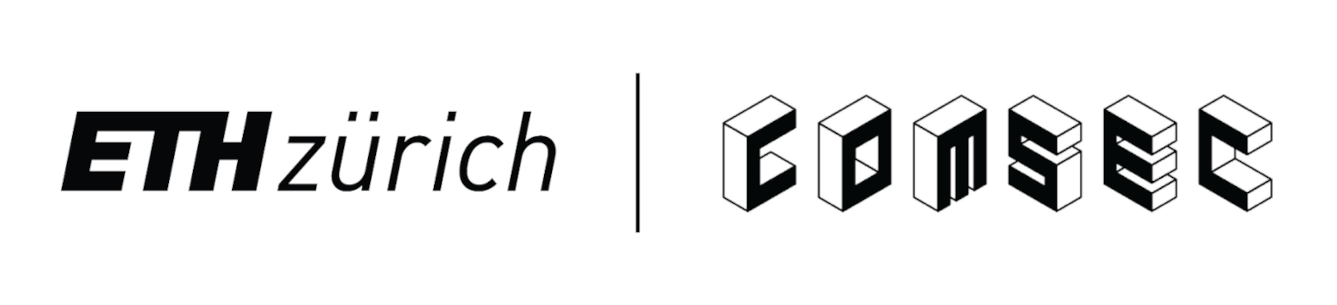
| Figure: Data acquisition using McSee. After the oscilloscope is configured (1), the experiment workload is executed while triggering the oscilloscope acquisition (2). Once the RAM disk is full (3), the data is copied to the decoding server. After acquiring sufficient traces (4), the remaining files are copied, converted into CSV files, and decoded into DRAM commands (5). | Figure: McSee hardware setup. The oscilloscope and the digitizer are connected to the experiment host’s DDR5 bus via an interposer, and an analog probe is used to trigger the recording. |
Analyzing Advanced Attacks
Equipped with McSee, we analyzed two advanced Rowhammer attacks from previous work on DDR4: (i) Sledgehammer shows that Rowhammer attacks can be made more effective by hammering multiple banks in parallel, and (ii) Rowpress presents a new Rowhammer-like effect where aggressor rows are kept open for longer to trigger bit flips rather than solely hammering them.
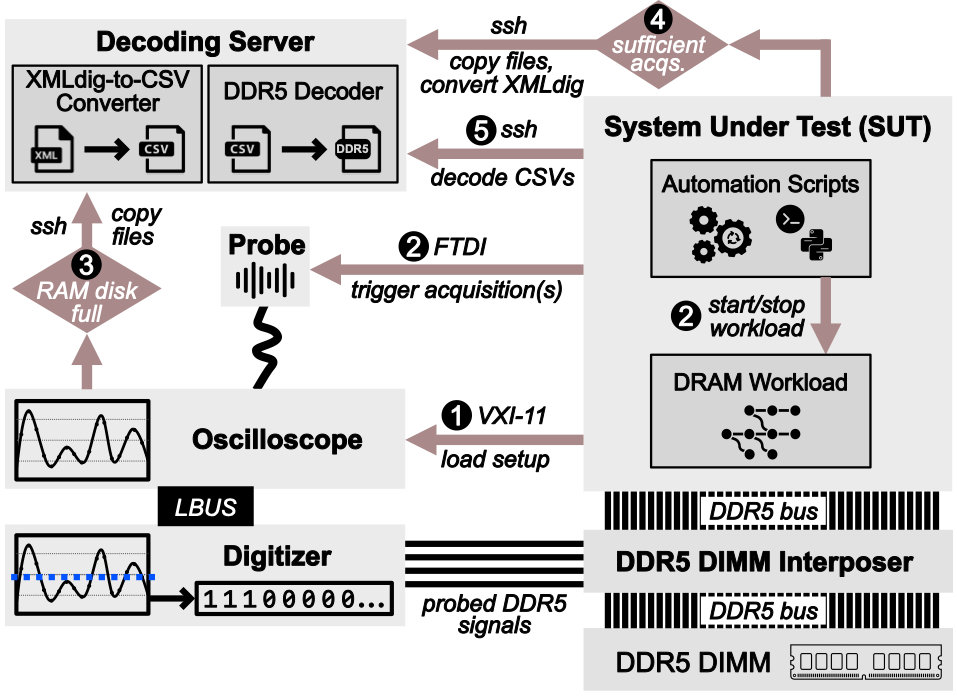
We reproduce Sledgehammer using their open-source implementation and take captures with McSee to analyze the activation throughput. We can see that the total activation throughout increases linearly up to six banks (715 ACTs), while the activation rate per bank slightly decreases from an initial 140 ACTs per bank to 119 ACTs per bank. Hammering seven or more banks, however, results in a significant drop in the number of activations per bank, which may make bypassing TRR more challenging. In our paper, we also leveraged McSee to look into reordering of accesses when hammering more banks.
 |
| Figure: Sledgehammer – average activation throughput per tREFI, per bank (line) and over all banks (bar), for different numbers of hammered banks (x-axis). |
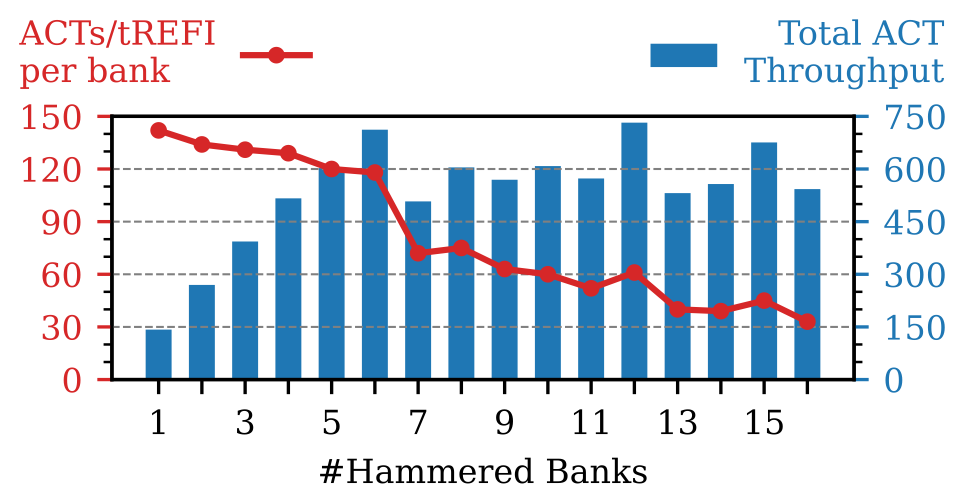
We then focused on Rowpress by reproducing their real-system demo code on the same machine as they used in their evaluation. We sweep over all different numbers of cache block reads per aggressor row activation (1-128) while capturing traces with McSee. We put this data into perspective with the ACmin data from the original study, indicating by how much less we need to hammer when combined with Rowpress. We find that on the PC, we can keep the row open for at most 292.95 ns, which decreases ACmin by a factor of 2 rather than the reported 17.6x ACmin decrease in their paper for the most effective Rowpress pattern. This result demonstrates that building an effective Rowpress attack is challenging, and there is room for improvement in making it more effective at bypassing TRR.
 |
| Figure: Rowpress – average row open time (tAggON) measured over 1 ms captures for different numbers of cache block reads (y1-axis, dot), compared to ACmin (y2-axis), the minimum number of activations to trigger the first bit flip as reported in [16] from an FPGA. |
Analyzing Deployed Mitigation
In the final part of our work, we explore the current landscape of deployed Rowhammer mitigations. More specifically, we aim to determine if Refresh Management (RFM) — a feature of the DDR5 standard intended to facilitate Rowhammer mitigations — is supported by DRAM DIMMs and recent CPUs.
We begin by examining RFM on DDR5 DIMMs by implementing a SPD chip decoder that can extract RFM-related fields. We find that 63% of the 30 devices advertise valid RFM values, but only 3% of these devices require it. We further confirm, using datasheets, that 77% of the DIMMs report implementing on-die ECC in their DRAM chips. To investigate RFM on the memory controller, we first reverse-engineer the Intel Alder Lake and Raptor Lake DRAM addressing functions using a new systematic bit-flipping technique enabled by McSee. Equipped with these functions, we run various Rowhammer workloads on both AMD and Intel machines, but we do not find any RFM commands. Instead, we find that Intel employs the fine-granularity refresh mode, effectively halving the standard tREFI of 3.9us. More surprisingly, we find that occasionally activations are sent to aggressor-adjacent rows on Raptor Lake, which reminds us of earlier reports about pTRR on Intel server CPUs.
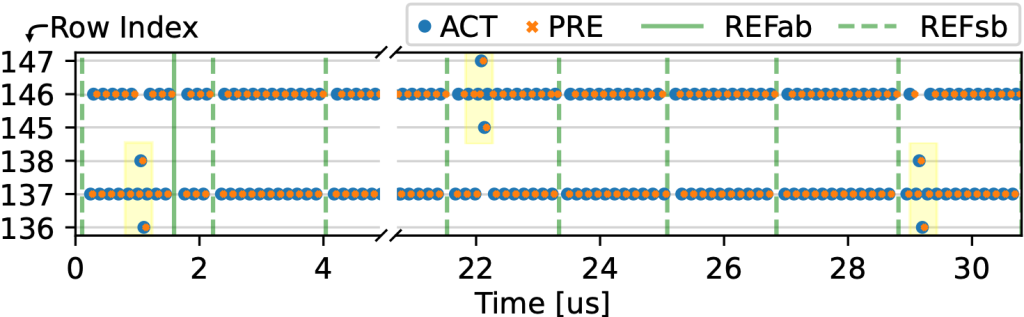 |
| Figure: Activations to aggressor-adjacent rows on the Intel Alder Lake system while hammering aggressor rows 146 and 137. |
We design an experiment to reverse-engineer the behavior of this pTRR mitigation by analyzing the probability that an aggressor’s adjacent row is activated. Analyzing the data captured by McSee reveals that these mitigative activations follow a binomial distribution, and aggressor-adjacent rows are refreshed with a probability of 0.091%. We also analyze the impact of pTRR on the security. Devices protected with pTRR and a Rowhammer threshold of 13200, 16700, and 18800 activations can be bypassed with roughly 50% attack success probability in less than an hour, one day, and one week, respectively.
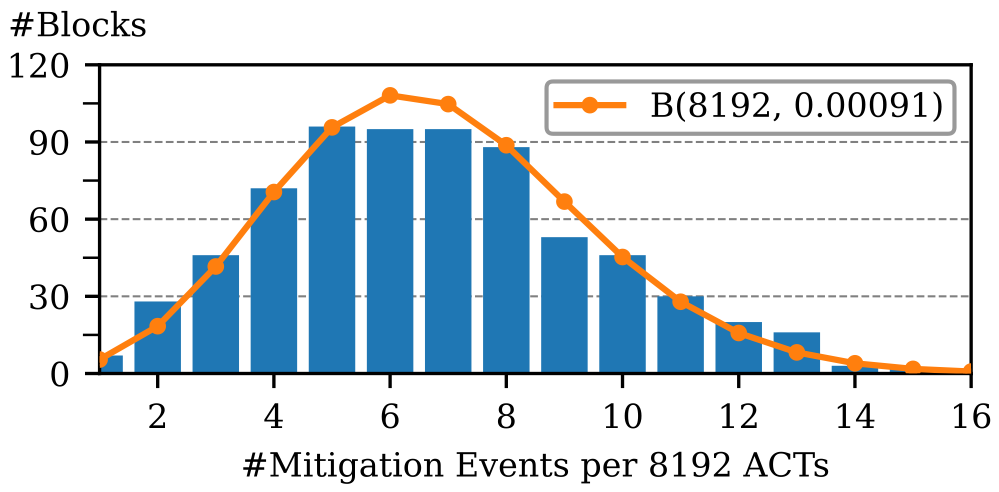 |
| Figure: Distribution of Intel pTRR mitigation events on Raptor Lake while hammering the aggressor pair 8192 times, collected over four captures with each 512 repetitions. The result corresponds to a binomial distribution with a probability p = 0.00091 (0.091%). |
Further Information
For more information about our work, please refer to our paper, which is to appear at USENIX Security 2025 in August 2025. Our McSee platform will soon become available on GitHub.
FAQs
Following, we answer the most frequently asked questions about our work.
Why did you build McSee if there are FPGAs available?
We built McSee because FPGAs do not allow for studying the behavior of memory controllers. We believe that McSee is a valuable platform not only for studying future DDRx protocol features, such as PRAC, but also for other memory-related analyses.
How can I use McSee in my projects?
The McSee platform is fully open source on GitHub, including the DDR5 UDIMM interposer PCB, the SPD decoder, and the DDR4/5 decoder. We list our full hardware setup in Section 3 (Table 1) of our paper. As our DDR4/5 decoder is platform-agnostic, it can also be easily used with any other oscilloscope, provided it can generate a CSV file of the captured trace.
Is it possible to use McSee with RDIMMs?
In theory, yes. However, as we discuss in §4.5, due to the different pins and fewer C/A lines resulting from ECC, changes to the interposer design and the decoder are necessary.
What else can I do with McSee?
McSee enables many memory-related analyses, for example, verifying DRAM timings when designing Rowhammer mitigations (as we did for REGA), studying DDRx protocol features such as fine-granularity refresh mode, or optimizing parts of Rowhammer attacks, like refresh synchronization (as we did for ZenHammer). Of course, McSee can also be helpful for many other scenarios unrelated to Rowhammer.
Do the results from Rowpress’ scope-based analysis show that the Rowpress effect does not exist?
No. We are demonstrating that in the case of the real-system demonstration, the attack is pressing (i.e., keeping the row open) for only a short time, revealing potential for future attack improvements.
Why is there no existing work showing bit flips on modern DDR5 devices, given that AMD does not seem to deploy pTRR?
The hammer count analysis in our recent work, REFault, indicates that the minimum hammer count (HCmin) of DDR5 DIMMs falls within the same range as that of DDR4 DIMMs. We argue that modern DDR5 devices likely employ more advanced Rowhammer mitigations, which have not yet been studied
Does it mean that Intel systems are, thanks to pTRR, safe against Rowhammer attacks?
This is unclear and depends on the strength of existing in-DRAM DDR5 mitigations.
Acknowledgments
We thank our anonymous reviewers and shepherd for their valuable feedback. This research was supported by the Swiss State Secretariat for Education, Research and Innovation under contract number MB22.00057 (ERC-StG PROMISE).